
It’s important for engineers to optimize for speed as much as possible. By solving performance problems, we can ensure advertisers don’t miss out on auctions and that publishers receive the bids needed to maximize revenue. The speed of our platform is crucial in making these auctions happen, which is why we closely monitor our elastic load balancing (ELB) surge queue. We want to share how we recently remedied capacity issues after noticing a case with an unusually high surge queue length.
What Is AWS Elastic Load Balancing?
In layman’s terms, a load balancer is something between a client and a number of backend instances that distributes client requests evenly. Of course, there is a lot of additional magic happening behind the scenes, such as health checks, but we can save that for next time.
With Amazon Web Services (AWS), everything is elastic. We have auto-scaling for backend instances, such as when we get a spike in client requests — and the same applies for a load balancer. A small load balancer is just one physical instance with one IP address. Simply put, all DNS requests to our platform will resolve to the one IP address of that single ELB node, and this machine will distribute requests to backend instances.
The Smaato Exchange is a massive system that has an ELB with many physical machines that scale in and out similar to backend instances. But this magic is all hidden behind the AWS ELB offering. It’s all handled automatically with Route 53, ASG, and so on.
Ideally, the client uses all available ELB nodes equally for its requests, so that the load on the ELB nodes is distributed evenly. However, that’s not always the case.
What Is Surge Queue Length?
According to AWS documentation, surge queue length is:
The total number of requests that are pending routing. The load balancer queues a request if it is unable to establish a connection with a healthy instance in order to route the request. The maximum size of the queue is 1,024. Additional requests are rejected when the queue is full. For more information, see SpilloverCount.
Ideally, that surge queue length is zero. Some occasional spikes may occur, but they should not persist. The most widely accepted cause for a surge queue is that there are not enough backend instances that can handle the requests coming into the ELB. Then the ELB queues the requests and eventually is able to either send them to a backend instance or reject them. The rejections are measured with the SpilloverCount.
Diagnosing a High ELB Surge Queue Length
In one of our regions, we noticed that we had an above-average surge queue length. Since the SpilloverCount was quite low, this issue wasn’t as big of an issue as it could have been, but we still moved quickly to solve the issue.
In the below graphic, you can see the metrics of the problematic availability zone (AZ) on the top row. The bottom row shows one of our other AZs that was always showing good metrics.
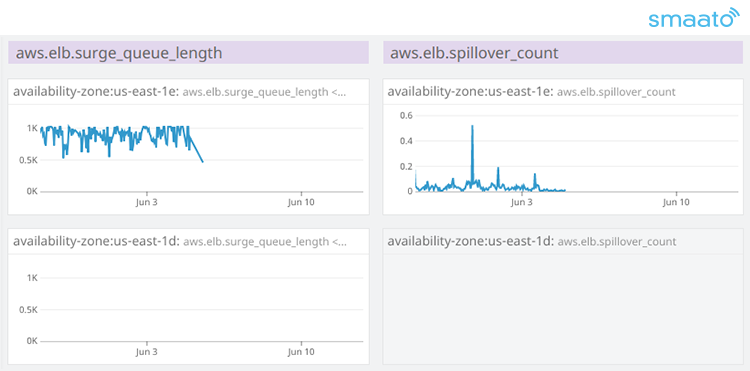
The fact that just one availability zone (AZ) was affected indicated that it may not have been a general backend capacity issue. Rather, it seemed that something else was causing these long surge queues. The load balancer on the Smaato Exchange is cross-AZ, so if one of our exchange’s AZs would have had problems, we would have seen that on all load balancer AZs — not just one. Additionally, we were not able to find any badly behaving backend instances. Everything in that particular AZ was fine. SpilloverCount was also very low, yet the surge queue metric in that AZ indicated a problem.
Check With AWS
Before speculating further, we opened a support chat with AWS, chose the severity level “production system impaired,” and waited. After ten minutes, someone picked up the chat and we started working on the problem. The AWS support engineer had far more metrics on the ELB than we could access. This included being able to look at individual ELB nodes, whereas our finest granularity of looking into the ELB is on the AZ level. The support engineer said that he saw problematic metrics on two specific ELB nodes/IP addresses. We had to upload ~50 gigabytes of ELB access log files for those two nodes.
The AWS support engineer monitored the files overnight and came back with the explanation that this seemed to be a client issue. A few clients (identified by him via the source’s IP addresses) were sending the majority of their requests to those two ELB IP addresses, rather than following the round-robin approach described above. That caused an uneven load on those instances and caused an increase in the surge queue.
Seek New ELB Nodes
We did a reverse lookup and further analyzed the ELB access logs. From the analysis, we were able to conclude that one of our publishers was inadvertently causing the problem. We worked together with the publisher but didn’t discover any issues that could be leading to the surge queue length.
After acknowledging that the client was not at fault, we asked AWS support to give us fresh ELB nodes in the region where we were having the issues. They replaced three of the most problematic nodes and the ELB surge queue was gone.
Key ELB Takeaways
After all that work, our problem was solved — but we weren’t able to determine the exact root cause for the ELB surge queue length. Still, the whole process was a valuable learning experience. The three main takeaways were:
- AWS’ ELB is still something of a black box. We can only see a limited set of metrics and not very granular. We had to work with AWS in order to get the finer details.
- The ELB surge queue not only indicates problems of the backend instances but also for the ELB itself.
- When starting a chat with AWS, setting the severity level to “production system impaired” will often get you faster feedback.



